HiOCR是一款面向新手的批量OCR(文字识别)工具,专为零基础用户处理大量PDF文档和图片设计:Windows系统下,双击exe文件打开界面,拖入文件/文件夹即可自动排队,一键开始后全程可视化进度,识别完成自动导出 Markdown文件,无需学习复杂参数与命令。本软件完全免费!
软件名称:HiOCR
最新版本:v2.3
适配系统:Windows 10/11等系统
开发者:马光
下载与更新地址1:
https://pan.baidu.com/s/1WchKiuVp9kKkqj4yqSBg4Q?pwd=6666 提取码: 6666
下载与更新地址2:
https://github.com/maguang/HiOCR
开箱即用:适用于Windows 10/11系统,直接双击exe即可运行。
批量处理:支持拖拽文件夹或多个文件,自动队列处理。
多模型支持:集成MinerU(免费)、硅基流动(DeepSeek-OCR、GLM-4.1V-9B-Thinking,二者均免费)、阿里通义千问、字节豆包、Google Gemini等。支持自定义模型ID。
智能识别:利用大模型能力,识别文字、保留表格结构,尤其是部分模型擅长处理中文古籍。
结果导出:自动保存为 Markdown (.md) 格式,方便编辑和阅读。.md文件可以右键使用“记事本”打开,也可以下载安装Typora、MarkText、VS Code等打开。
API 配置
在配置面板提供多个AI 模型服务商选项。支持“自定义模型”功能:选择下拉列表末尾的“自定义模型”,可输入任意兼容的模型 ID。
参数调整
支持调整并发线程数(提高速度)、PDF 渲染 DPI(提高清晰度)。
任务管理
·添加文件:点击按钮或拖拽文件/文件夹到待识别区域。
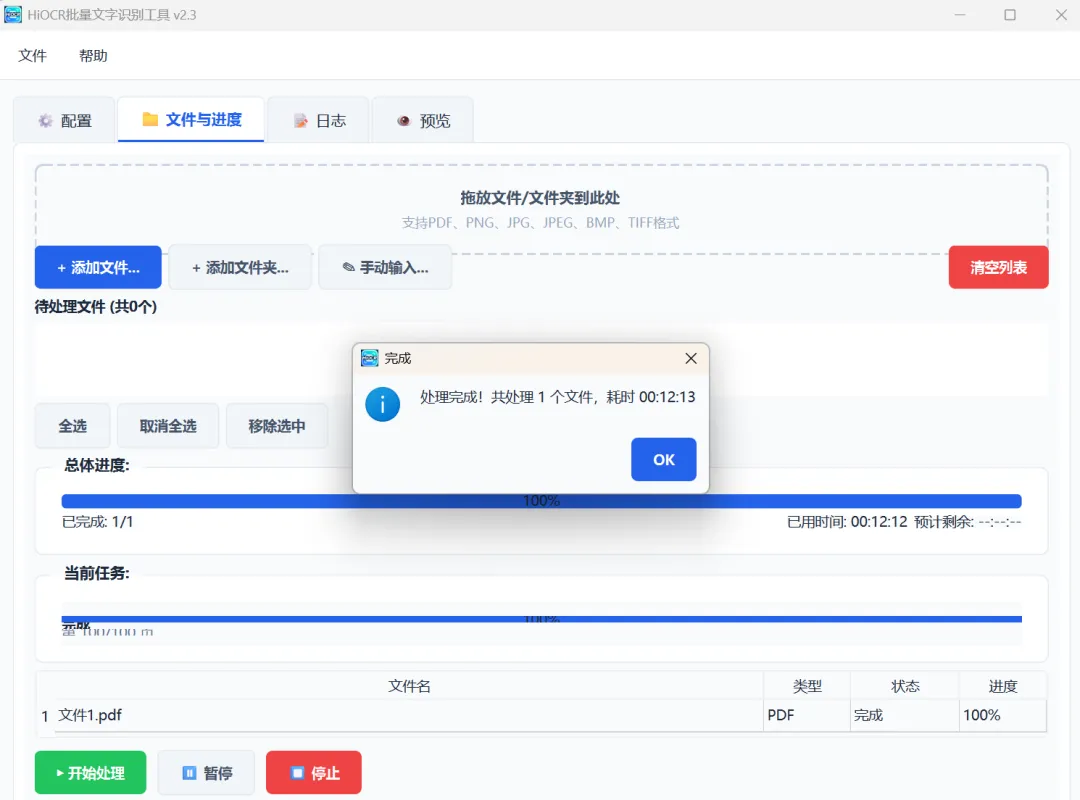
·进度监控:实时显示总进度、当前文件进度、页数进度。
·自动清理:识别成功的文件自动移出列表,失败的文件保留以便重试。
结果查看
输出到用户自定义目录(默认输出到“D:\OCR输出”)。
不同模型各有千秋,建议根据文档类型选择:
1. MinerU (官方 API)
参考地址:
https://mineru.net/apiManage/docs
推荐场景: 学术图书论文 / 复杂 PDF 布局 / 导出 Markdown。
优点: 免费,每天至少2000页额度;由 OpenDataLab 开发,专为 PDF 版面分析优化,公式与表格提取能力强。
缺点: 中文古籍识别效果较差;单个文件有大小和页码限制:≤200M,≤600页。
2. 硅基流动 (DeepSeek-OCR、GLM-4.1V-9B-Thinking),免费
参考地址:
https://cloud.siliconflow.cn/
推荐场景: 通用文档 / 代码识别 / 高性价比方案。
优点: 免费额度高,推理速度快。
缺点: 复杂版面还原度稍逊,精确度不高,中文古籍识别效果较差。
3. 字节豆包 (Doubao)
参考地址:
https://www.volcengine.com/docs/82379/1541594?lang=zh
推荐场景: 中文古籍 / 普通文档和图片 / 快速识别。
优点: 中文语义理解能力强,响应速度快,对常规古籍识别效果良好。
缺点: 有敏感词监测。
4. 阿里通义千问 (Qwen)
参考地址:
https://help.aliyun.com/zh/model-studio/get-api-key?spm=0.0.0.i1
推荐场景: 综合首选 / 中文古籍 / 复杂排版还原。
优点: 识别率顶尖,对古籍、手写体和竖排文字支持极好,版面还原度最高。
缺点: 监测较严,会拒绝识别带有敏感词的整页内容。
5. 智谱 GLM (ZhipuAI)
参考地址:
https://docs.bigmodel.cn/cn/api/introduction
推荐场景: 中文古籍 / 普通文档和图片 / 中文长文档处理。
优点: 商用性价比高。
缺点: 在极高分辨率图片的精细识别上,相较于 Qwen3-Max 略有差距。
6. Google Gemini
参考地址:
https://aistudio.google.com/app/api-keys?hl=zh-cn
推荐场景: 外文文档 / 多语言混合 / 极长文本。
优点: 全球领先多模态能力,多语言支持极佳,支持超长上下文。
缺点: 在国内使用需要特殊的网络环境 (VPN)。
[推荐配置]* 识别中文古籍:强烈推荐通义千问、豆包。* 识别普通文档:可以使用MinerU、 DeepSeek-OCR、智谱 GLM。
本软件基于大模型 API,需要您自行申请并填入 API Key。
1. MinerU(官方 API)
1)访问:
https://mineru.net/,注册并登录。
2)在官网申请 Token(API Token)。
3)将 Token 填入软件的 API Key(或 Token)字段。
4)如软件需要填写鉴权方式,请使用:Authorization: Bearer <Token>
5)注意:如遇失败,请检查文件大小与页数是否超限(例如:200MB、600页等限制)。
2. 硅基流动 (DeepSeek/VLM)
1)访问:
https://cloud.siliconflow.cn/
2)注册账号(通常有免费额度)。
3)生成 API Key 并填入软件。
3. 字节豆包
1)访问:https://console.volcengine.com/ark/
2)创建推理接入点,获取 API Key。
3)将 API Key 填入软件。
4. 阿里云通义千问 (Qwen)
1)访问:https://bailian.console.aliyun.com/
2)登录并开通“模型服务”。
3)在“API-KEY 管理”中创建新的 API Key。
4)复制 Key 填入软件,Base URL 默认即可。默认地址:
https://dashscope.aliyuncs.com/compatible-mode/v1
5. 智谱 GLM(ZhipuAI / GLM)
1)访问:
https://open.bigmodel.cn/ ,注册并获取 API Key。
2)将 API Key 填入软件。
3)Base URL(OpenAI 兼容方式)填写:
https://open.bigmodel.cn/api/paas/v4/
6. Google Gemini
1)访问:Google AI Studio:
https://aistudio.google.com/,在“API Keys”页面创建并管理 Gemini API Key。
2)将 Key 填入软件。
Q: 如何打开md文档?
右键 ->使用windows系统自带的记事本打开。或下载 Typora、MarkText、VS Code等打开。
Q: 点击”开始处理”没有反应?A: 请检查是否添加了文件,且 API Key 是否已正确设置并通过测试。文件上传和PDF拆分预处理,都需要一定的时间,所以大的PDF文档加载也需要一定的时间,请耐心等待。
Q: 识别结果乱码或为空?A: 可能是 PDF 每页图片过大导致模型拒识,尝试调低 DPI (如 150)。此外,有些模型,比如Qwen内嵌有敏感词检测,触发时,也会无法识别,这个和大语言模型有关,无法避免。
Q: 文件名乱码?A: 本软件全程支持 UTF-8,确保您的系统路径没有特殊偏僻字符。
本次更新主要增强了软件的模型扩展能力与视觉识别度,并引入了更多的高性能免费模型。同时,我们重构了多线程逻辑以提升批量处理效率。
✨ 新增功能与外观
自定义 AI 模型支持:不再局限于预设列表,现在您可以手动填入任何兼容的 AI 模型名称。这为您尝试最新的推理模型或自建服务提供了极大的灵活性。
新增软件 Logo:正式上线了应用程序图标(Logo),修复了此前图标缺失的问题,提升了软件在任务栏与桌面的辨识度及整体美观性。
🚀 性能与稳定性
多线程性能优化:对底层的多线程处理机制进行了重构与优化,在处理大量文件时资源调度更合理,显著提升了并发识别的速度与运行稳定性。
🤖 模型生态更新
接入硅基流动(SiliconFlow)新模型:
新增免费模型:THUDM/GLM-4.1V-9B-Thinking,不仅免费且具备强大的思维链能力。
新增高阶模型:Qwen/Qwen3-VL-235B-A22B-Thinking 与 Qwen/Qwen3-VL-8B-Instruct,满足不同精度的识别需求。
优化通义千问模型列表:重新梳理了阿里云通义千问的模型选项,移除了过时条目,确保列表整洁且易于选择。
💡 体验改进
文案表达优化:全面校对并优化了界面上的提示文字与功能说明,修正了歧义表述,让操作指引更加清晰易懂。
HiOCR 为免费公开软件,但默认不授予商业用途的使用许可。
本项目代码采用 PolyForm Noncommercial License 1.0.0(SPDX: PolyForm-Noncommercial-1.0.0)授权:
1)允许个人/学校/科研/公益等非商业目的:使用、修改与分发。
2)禁止任何商业目的使用(包括但不限于:将本软件/源码集成到收费产品、以本软件提供收费服务、为商业项目交付/代跑/代处理等)。
3)如需商业授权(个人免费 + 企业付费):请联系作者取得书面商业许可。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
