YOLO 到底该怎么学:从下载安装到自定义训练,一篇讲透学习路线、数据集、硬件和避坑
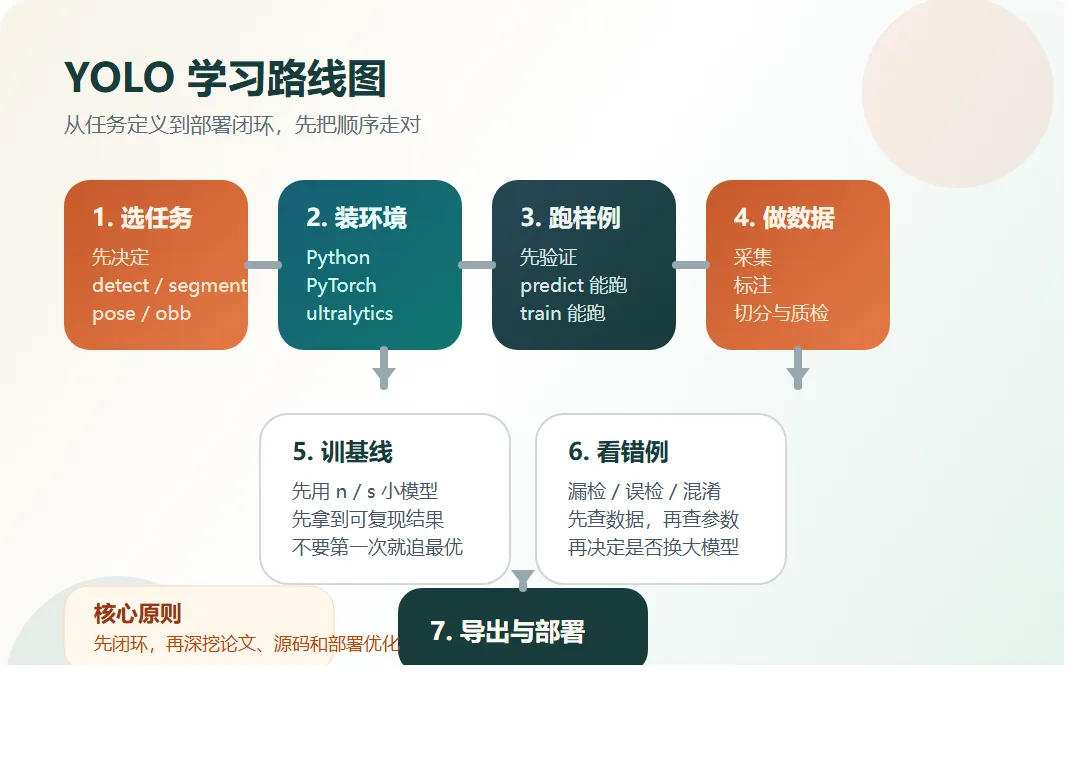
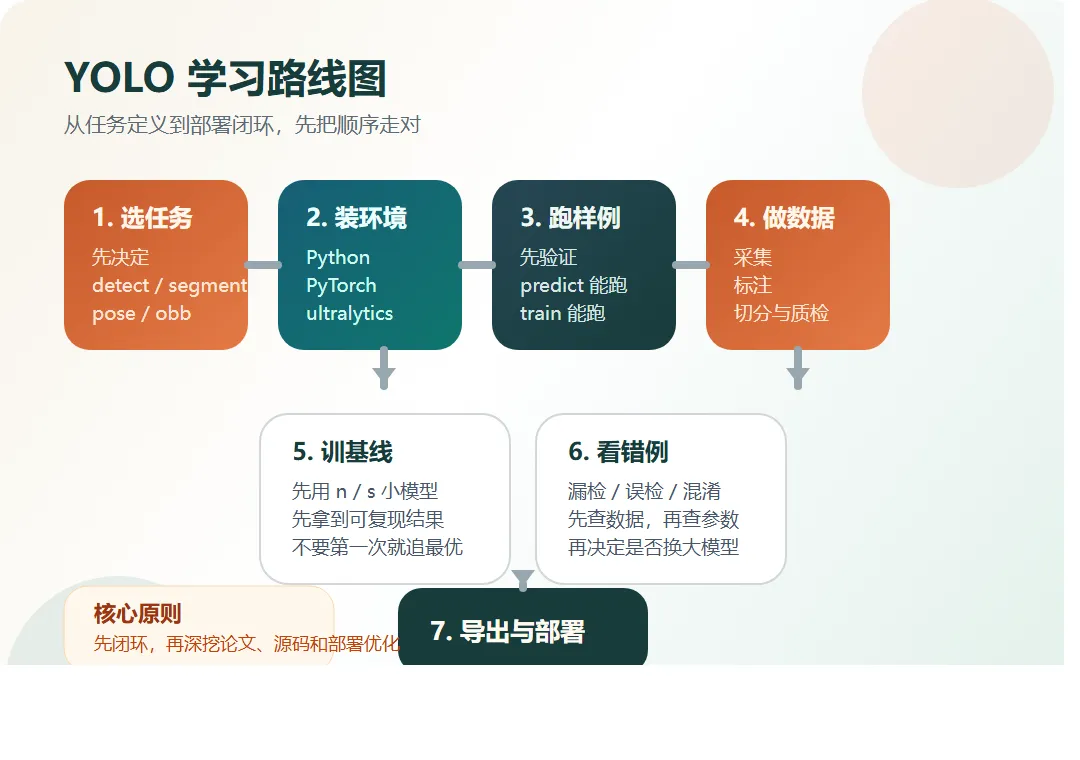
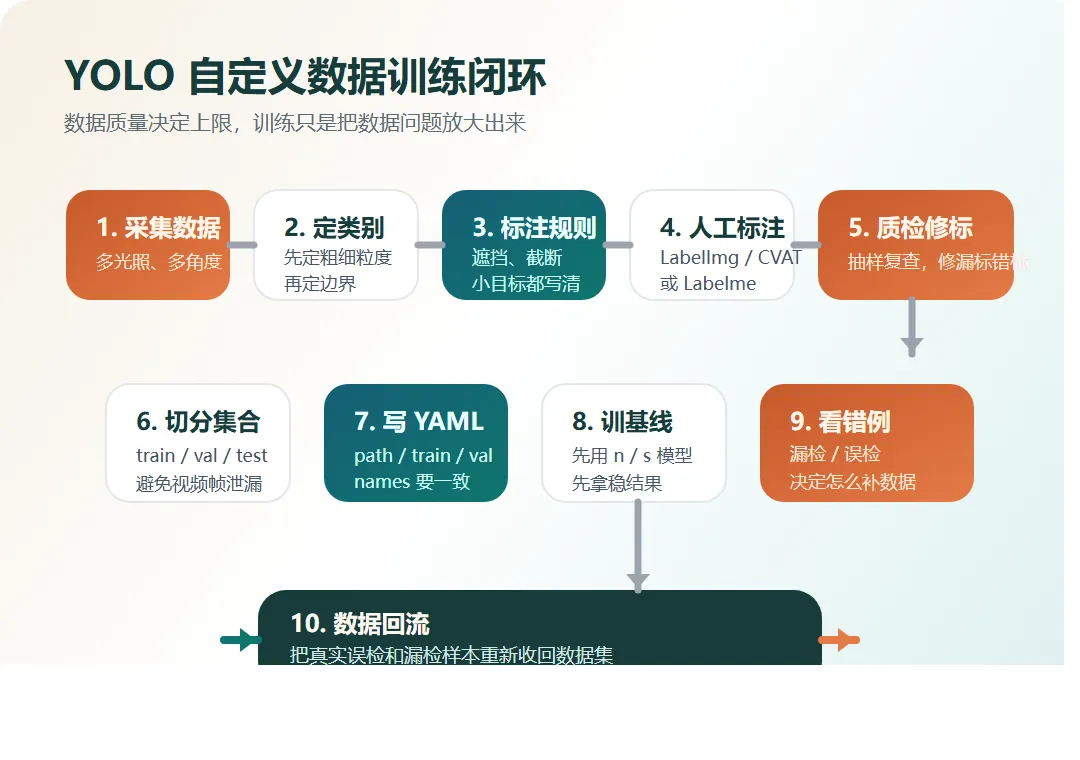
很多人学 YOLO,一上来先搜一堆零散教程,然后在 YOLOv5、YOLOv8、YOLO11、YOLO26 这些名字里来回切换,最后不是环境装崩,就是数据集没做好,或者跑出一个看起来有 mAP、落地却完全不好用的模型。真正的问题,往往不是你不够努力,而是学习顺序错了。如果你现在是从零开始,最稳的路线不是先争版本,也不是先啃论文,而是先把任务、环境、数据、训练闭环和部署闭环走通。只要这条线走顺,后面你再看源码、换模型、做优化,才会越来越清楚。截至 2026-04-03,Ultralytics 官方文档首页展示的最新主线模型已经是 YOLO26,同时官方明确写了稳定生产场景可优先考虑 YOLO26 和 YOLO11。所以如果你是新学者,我更建议你按“通用 YOLO 方法论 + Ultralytics 主线实操”的方式入门,而不是从更老的版本开始兜圈子。1. YOLO 到底该学什么,而不是被版本号带偏。3. 电脑硬件至少要到什么程度,才适合真正开始训练。6. 第一轮训练参数该怎么配,哪些参数先动,哪些后动。7. 模型训完以后该怎么看结果、怎么导出、怎么部署。你要学的是一套目标检测和视觉建模的方法,而不是死记某个版本号。也就是从早期 YOLO 系列一路发展过来的检测思想,包括单阶段检测、实时推理、端到端改进、多任务扩展这些脉络。对于大多数初学者来说,你真正每天打交道的,不是论文 PDF,而是具体实现、训练脚本、数据格式、导出方式和部署工具链。现在最常见、文档最完整、上手成本最低的一条主线,就是 Ultralytics 的这套工程化 YOLO 生态。• 你只想学方法论和完整流程:直接用 Ultralytics YOLO 主线。• 你是全新项目,想用最新主线:优先从 YOLO26 开始。• 你所在团队已经有成熟存量项目:兼容 YOLO11 或项目既有版本。• 你看的教程还停在更老版本:可以借它理解思路,但不要把老版本教程当成今天的默认工程入口。Ultralytics 当前同一套框架里,已经支持这些任务:• classify:图像分类,整张图只出一个类别结果。• obb:带旋转角度的目标检测,适合遥感、文档、工业场景。如果你是第一次学,我建议你先把 detect 学透。因为检测任务最容易建立从数据到结果的闭环。等检测这条线跑顺了,再进阶到分割、姿态或 OBB,成本会低很多。正确顺序不是“先啃所有原理,再去碰代码”,而是下面这条线:3. 先跑通官方样例,确认代码、CUDA、依赖都没问题。6. 再根据错误样本去调数据、调参数、调模型规模。你会发现,这条顺序里,真正最重要的不是“训练”本身,而是“闭环”。• 官方样例可以预测,也可以训练 1 个 epoch。• 如何切分 train / val / test。如果你只会 train,其实还不算真的会 YOLO。• onnx、TensorRT、OpenVINO 这些格式什么时候该用。YOLO 可以在 CPU 上跑,但如果你真的想认真学训练,最好还是有一张支持 CUDA 的 NVIDIA GPU。官方文档没有给出一个唯一的“最低硬件标准”,但从当前主线模型的参数量、FLOPs、批大小控制方式、多 GPU 支持和混合精度配置来看,硬件选型至少应该按训练目标来分层。下面这份配置建议,是我基于官方模型规模和训练配置做的工程经验判断,不是官方硬性最低要求。• 在极小数据集上试 1 到 3 个 epoch。• NVIDIA GPU,显存 8GB 到 12GB。• NVMe SSD,最好预留 200GB 以上可用空间。• CPU 至少是近几年主流 6 核到 12 核处理器。如果你已经是团队项目、需要更稳定的训练吞吐,或者要跑更大的模型,才有必要考虑:• device=-1,-1 自动选择两张最空闲 GPU。如果你现在要买或配一台用于学习 YOLO 的机器,我更建议你按这个思路选,而不是只盯某个具体型号:• 优先保证有可用 NVIDIA CUDA GPU。• 优先保证 32GB RAM,否则数据加载和多进程经常拖后腿。• 优先保证 NVMe SSD,数据集、缓存、权重和导出文件都会吃磁盘。PyTorch 当前官方页面写得很明确:最新稳定版要求 Python 3.10 或更高。• Windows 激活:.venv\\Scripts\\activate• Linux 或 macOS 激活:source .venv/bin/activate不要先乱装 ultralytics,再回来补 PyTorch。当前 PyTorch 官方安装页显示,稳定版是 2.7.0,并提供 CUDA 11.8、CUDA 12.6、CUDA 12.8 和 CPU 选项。你要做的不是死背命令,而是去官方安装页选与你机器一致的组合。如果你当前环境就是 CUDA 11.8,官方给出的 pip 示例是:• pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118如果你没有 NVIDIA GPU,或者只是先学习流程,也可以先装 CPU 版本。Ultralytics Quickstart 当前给出的最直接安装方式是:• pip install -U ultralytics• conda install -c conda-forge ultralytics如果你在 CUDA 环境里使用 Conda,最好把 ultralytics、pytorch、pytorch-cuda 放在同一条命令里一起安装,或者最后再单独安装 pytorch-cuda 覆盖 CPU 版依赖。• python -c "import torch; print(torch.__version__); print(torch.cuda.is_available())"• python -c "from ultralytics import YOLO; print('ok')"• yolo predict model=yolo26n.pt source='https://ultralytics.com/images/bus.jpg'因为环境没通的时候,你后面的所有报错都会混在一起。• WSL 适合同时想保留 Windows 桌面环境,又希望训练环境更接近 Linux 的人。如果你以后准备走服务器、多卡、Docker、部署这条线,那 Linux 经验会更有价值。环境刚装好,马上上自己的数据、自己的类别、自己的路径、自己的标注工具、自己的增强策略。• yolo predict model=yolo26n.pt source='https://ultralytics.com/images/bus.jpg'• yolo detect train data=coco8.yaml model=yolo26n.pt epochs=1 imgsz=640• 你会先知道 weights、results、日志、验证图这些文件在哪里看。六、数据集怎么做:这是学 YOLO 最该花时间的地方YOLO 的上限,通常不是先被模型卡住,而是先被数据卡住。数据集不是“图片凑够数”就行,而是要围着你的真实任务去设计。如果你只是要判断“有没有车”,那 vehicle 一个大类就够了。但如果你要做违停、收费或车型分析,可能就要细分到 car、bus、truck、motorcycle。所以不要为了“显得专业”而一开始就把类别拆得特别碎。Ultralytics 的数据采集指南强调得很明确:如果训练集全是“理想状态高清大图”,落地后一定翻车。只要规则不统一,模型学到的就不是“目标”,而是“标注员习惯”。Ultralytics 官方数据标注指南里列了几类常见开源工具,比较适合初学者入门:• LabelImg:框选最快,上手成本低,适合检测任务。• Labelme:多边形操作直观,适合更细的轮廓标注。• Label Studio:任务类型更灵活,项目管理能力更强。• 单人、小项目:先用 LabelImg 或 CVAT。• 如果做迁移学习和目标检测,每个类别至少先准备“几百个已标注目标”。• 如果你只训练一个类别,至少可以从 100 张已标注图片和大约 100 个 epochs 开始。• 更复杂的任务,往往需要每类上千张图片才能更稳。6. train / val / test 怎么切关键不在于你到底是 8:1:1 还是 7:2:1。• 同一段视频连续抽帧,不要一部分进训练、一部分进验证。• 同一场景、同一机位、同一分钟内拍的图,尽量只落在一个集合里。• names: {0: person, 1: helmet}• 你标注文件里的类别编号,必须和 names 完全一致。检测任务里,每张图片通常对应一个同名 .txt 标注文件。这些坐标一般都是相对于图片宽高归一化后的数值,也就是落在 0 到 1 之间。所以第一次做数据集时,一定抽样人工检查几十张图,确认框和类别都对。Ultralytics 的数据标注指南里一直在强调一致性、准确性、异常样本和质量检查。因为很多时候,模型差并不是“数据不够”,而是“脏数据太多”。七、第一轮训练怎么配:先拿一个稳基线,不要一上来乱调新手最好的策略,不是“第一次就训到最优”,而是先拿到一个可复现的基线。• 模型先用 yolo26n.pt 或 yolo26s.pt你第一阶段的目标不是“榨干精度”,而是先确认数据没问题、训练逻辑没问题、验证逻辑没问题。• yolo detect train data=dataset.yaml model=yolo26n.pt epochs=100 imgsz=640 batch=-1 device=0 workers=8• yolo detect train data=dataset.yaml model=yolo26n.pt epochs=30 imgsz=640 batch=8 device=0 fraction=0.1官方训练技巧文档明确支持它用来抽取数据子集,特别适合快速排错和小步迭代。• device:使用哪张 GPU,或者 CPU。新手一上来最容易做错的一件事,就是同时改太多超参数。4. 关于 batch、cache、amp 的实用建议• batch=-1 可以自动选一个适合设备的批大小。• cache 可以减少磁盘 I/O 对训练的拖累。• amp=True 可以开启自动混合精度,提升训练效率。官方训练技巧文档明确建议优先用预训练权重,也就是迁移学习。• Precision:你报出来的目标里,有多少是真的。4. 再决定是补数据、修标注、换模型尺寸,还是调阈值。九、调参顺序怎么排:先动影响最大的,不要从枝节开始5. 再调整 imgsz、batch、epochs。6. 最后才去折腾更细的优化器、增强策略和进阶训练技巧。因为实际项目里,影响最大的通常不是“某个玄学参数”,而是:如果你数据本身就乱,换大模型通常只是更快地过拟合。如果你的小目标很多,或者原始图片分辨率本来就高,那提高 imgsz 往往有帮助。先在 640 上拿到稳基线,再考虑 768、960、1024。• 典型起点可以从 300 epochs 开始考虑。如果你的小数据集已经明显过拟合,那 300 反而太多。• 第一轮先跑 30 到 100 epochs 观察趋势。十、训练命令之外,你还得学会 val、predict 和 export• yolo val model=runs/detect/train/weights/best.pt data=dataset.yaml• yolo predict model=runs/detect/train/weights/best.pt source=demo.jpg• yolo export model=runs/detect/train/weights/best.pt format=onnxUltralytics 当前导出文档明确支持多个格式,包括 ONNX、TensorRT、CoreML、OpenVINO 等。如果你现在只是想先把模型带到别的工程里跑,最常见的第一步通常是:如果你后续部署平台很明确,再继续针对硬件选更合适的格式:• NVIDIA GPU:更偏向 TensorRT• CPU 优化:可以看 ONNX 或 OpenVINO十一、什么时候该学 detect、segment、pose、obb官方样例都没跑通,就去训自己的数据,报错会非常难定位。同一机位、同一背景、同一光照的几千张图,不等于强数据集。尤其是视频抽帧场景,这是最常见的“高分假象”来源。不做 predict、val、export 和部署联调,模型只是停留在实验室里。如果你后面要把 Ultralytics 这套能力放进商业产品里,记得提前确认 AGPL-3.0 和企业许可的边界,不要等项目临上线才补法务问题。如果你是工程师,白天还要上班,我更建议按 4 周节奏来,而不是试图一周速成。• 装 Python、PyTorch、Ultralytics只要你 4 周能把这条线跑完,你对 YOLO 的理解就已经超过很多“看过很多教程但没做过闭环”的人了。真正有效的学习路线,不是资料越多越好,而是顺序要对:做到这一步以后,你再去读论文、看源码、比较模型、做部署优化,效率会高很多。如果你也在学 YOLO,欢迎留言说说你现在最卡的是哪一段:如果你想看下一篇,我可以继续把这几个方向分别展开成单独实战文:• YOLO 从 best.pt 到 ONNX/TensorRT 的部署路线
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
