回到硬件服务器厂商工作快半年了,接触信创特别强调数据与工具使用的本地化以确保数据安全。相应的,AI工具也得本地化支撑起来。除了AI助手和AI知识库采用Cherry Studio搭建以外,其调用的模型也必须本地化,于是除了使用LM Studio方便的下载并本地运行LLM以外,以前常用的Ollama也得重新部署起来。由于Ollama的Windows安装包仍然不能调整软件的默认安装位置,其默认安装位置是:【C:\Users\win账户用户名\AppData\Local\Programs\Ollama】,且默认的模型存放位置是:【C:\Users\winds\.ollama\models】;往往普通人的C盘都处于容量焦虑状态,最好还是把Ollama下载的模型的存放位置从C盘调整到D盘等空间富裕的位置。
一、新版Ollama图形化调整模型存放位置
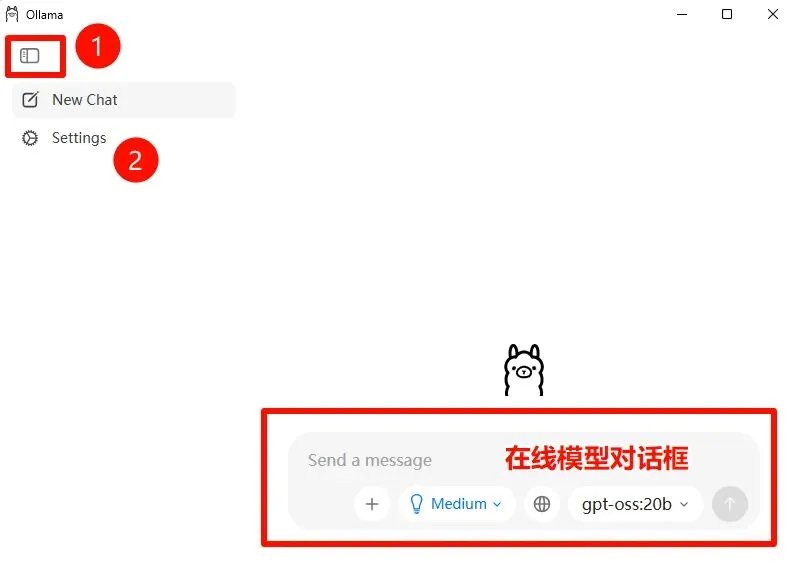
2025年12月底发布的“v0.13.5”版Ollama已经具备相当完善的图形化界面,软件启动后进入如下界面:
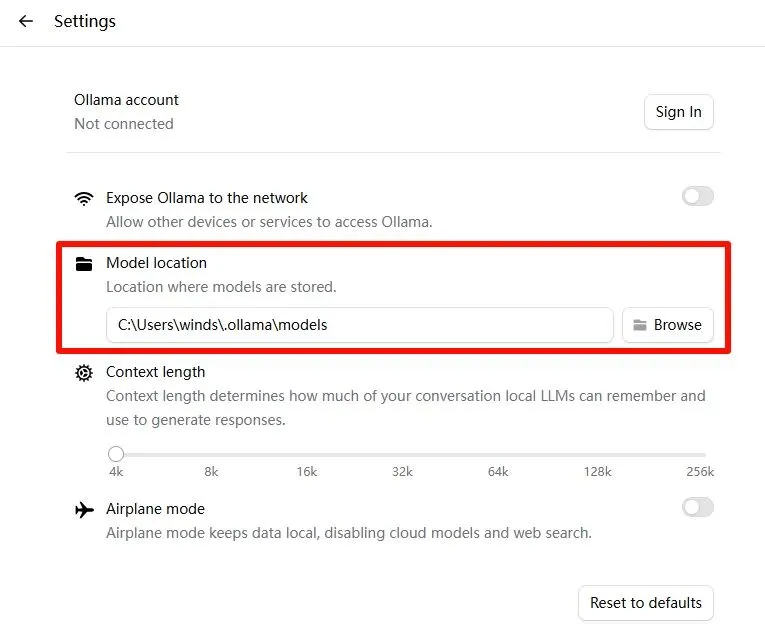
在主界面的隐藏按钮里找到“Settings”设置,进入就能修改模型存放位置“Model location”。
不需要登录Ollama账户体系也能正常Ollama的各项功能。
如果本机是个人电脑,不建议让Ollama为局域网的其他设备提供算力服务,“Expose Ollama to the network”不要打开;
“Model location”里面的文件夹路径调整为D盘的你希望的目录;
Ollama提供的模型上下文长度默认为4K,根据实际情况,可以稍微调大一点,比如调整到16K,这个参数也不是越大越好,一方面是受限于选用的模型本身能否支持,另外上下文长度越大,模型一次处理的数据量就越大,算力Tokens消耗就越大,耗时就越长。关于上下文长度与消耗Tokens的关系,我给一个简单的测算逻辑,可以大致自己评估一下:
大语言模型(如DeepSeek)单次处理的文本长度受硬件和算法限制。最大 Tokens 决定了模型单次请求能处理的 输入+输出 的 Tokens 总数上限。超过此值会导致截断或报错。 Token 并非严格等于单词或汉字。例如,英文中 1 Token ≈ 4 字符,中文中 1 汉字 ≈ 2-3 Token 在问答或生成场景中,该参数直接影响 AI 生成回答的最大长度。例如设置为 512,则回答内容会被限制在约 512 个 Token(约 380 个汉字或 700 英文单词)。
最后,如果就是自己本机使用Ollama的本地模型,则“Airplane mode”功能建议打开,让Ollama仅提供本机模型服务,也不会发送数据至网络上。当然,得等模型下载完毕后再打开此功能。
二、旧版Ollama的模型位置变更需调整系统变量
1. 创建目标文件夹:先在D盘创建用于存放模型的文件夹,例如 `D:\Ollama\models` 或 `D:\models_on_d`。
2. 设置环境变量:
- 打开系统环境变量设置
- 新建系统变量:
- 变量名:`OLLAMA_MODELS`
- 变量值:`D:\Ollama\models`(你创建的文件夹路径)
3. 重启生效:
- 关闭所有Ollama相关进程
- 重新打开命令行窗口
- 运行 `ollama -v` 确认安装正常
重要注意事项:
1. 原模型文件作废:修改路径后,原C盘路径(默认在 `C:\Users\用户名\.ollama\models`)已下载的模型文件将无法直接使用,需要重新下载到新位置。
2. 验证方法:
- 运行 `ollama list` 查看已下载模型
- 新下载的模型将存储在新设置的D盘路径中