导语
2026 年 4 月,阿里通义千问团队开源了 Qwen3.6-27B。这个 27B 参数的稠密模型在编程和智能体任务上,全面超越了前代 MoE 旗舰 Qwen3.5-397B-A17B,参数量只有后者的 1/15。如果你想知道怎么下载权重、怎么部署上线、怎么微调适配自己的任务、以及怎么验证模型跑没跑对,这篇就是为你准备的。全文约 4000 字,阅读需要 10 分钟。
这篇文章适合谁看
你手头至少有一张消费级显卡(RTX 3090 / 4090),或者有云 GPU 环境。你了解 Docker 和 Python 的基本操作,不需要分布式训练级别的部署。你在大模型落地中遇到了以下问题之一:不知道选什么量化档位、不确定哪种部署框架最适合自己、想微调但不清楚数据格式和参数怎么设。
如果你还不太熟悉 LoRA 和 ChatML,也没关系,本文的微调部分会连数据格式一起说明白。看完之后你至少能回答三个问题:我的卡能跑哪个量化版本?用 vLLM 还是 SGLang?微调数据长什么样?
模型下载渠道
模型权重已经上传到主流开源平台,直接下载即可,不需要申请权限。
Hugging Face 官方仓库:Qwen/Qwen3.6-27B(Apache-2.0 协议,无门禁)
ModelScope 镜像:Qwen/Qwen3.6-27B(国内用户更推荐走这个,下载速度比 HF 快得多)
GGUF 量化版:unsloth/Qwen3.6-27B-GGUF(llama.cpp 生态专用,社区也提供了 Q8_0、Q4_K_M 等主流量化版本)
AWQ-INT4 量化版:cyankiwi/Qwen3.6-27B-AWQ-INT4(vLLM 推荐,单卡 4090 可跑)
MNN 4-bit 端侧版:taobao-mnn/Qwen3.6-27B-MNN(阿里官方移动端推理优化版)
磁盘占用参考:FP16 权重约 55 GB,4-bit 量化约 18 GB,GGUF-Q8_0 约 28.6 GB。下载前确保有充足空间。
下载方式很简单,用 git lfs 或者 HuggingFace CLI 都行:
bash
# 方式一:Git LFS(完整权重,约 55 GB)git lfs installgit clone https://huggingface.co/Qwen/Qwen3.6-27B# 方式二:HuggingFace CLI(可指定子文件夹)pip install huggingface-hubhuggingface-cli download Qwen/Qwen3.6-27B --local-dir ./qwen3.6-27b
国内用户推荐走 ModelScope:
bash
pip install modelscopemodelscope download --model Qwen/Qwen3.6-27B --local_dir ./qwen3.6-27b
模型核心参数速览
把模型规格汇总成一个对照表,方便后面部署时参考:
| |
|---|
| |
| |
| |
| 混合注意力(Gated DeltaNet + Gated Attention) |
| |
| |
| |
| |
跟 Qwen3.5-397B-A17B 做一下对比就知道这个模型的定位了:同样的编程 Agent 能力,参数少了 93%,部署门槛从 8× A100 降到了 1–2 张消费卡。
多种部署方式
Qwen3.6-27B 支持的部署方案很多,从生产级推理框架到端侧推理都有覆盖。选哪个取决于你的硬件和场景。
方式一:vLLM(生产首选,推荐)
vLLM 对 Qwen3.6-27B 的支持最成熟,建议用 v0.19.0 以上版本。以下按硬件配置从低到高排列:
单卡 RTX 4090 运行 AWQ-INT4 量化版
bash
# 安装 vLLMuv pip install vllm# 启动服务,--tensor-parallel-size 不传(默认 1)vllm serve cyankiwi/Qwen3.6-27B-AWQ-INT4 \ --port 8000 \ --max-model-len 65536 \ --gpu-memory-utilization 0.9 \ --reasoning-parser qwen3 \ --trust-remote-code
选 AWQ-INT4 而不是原生 FP16 的原因:权重从 55 GB 压缩到约 20 GB,单张 24 GB 显存刚好装下,还能留出 4 GB 给 KV Cache 和推理开销。--max-model-len 设 65536 是平衡点——再高会 OOM。
双卡 A100/H100 运行 FP8 官方量化版
bash
vllm serve Qwen/Qwen3.6-27B-FP8 \ --port 8000 \ --tensor-parallel-size 2 \ --max-model-len 262144 \ --reasoning-parser qwen3
FP8 是官方推荐的量产方案,权重约 27 GB,质量接近无损。双卡 A100 可以跑满 262K 原生上下文。
开启 MTP 推测解码(加速 1.5–2×)
bash
vllm serve Qwen/Qwen3.6-27B \ --port 8000 \ --tensor-parallel-size 2 \ --max-model-len 262144 \ --reasoning-parser qwen3 \ --speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":2}'
MTP 是 Qwen3.6 内置的多 token 预测能力,每次推测输出 2 个候选 token,配上 vLLM 的 spec decode 管线,代码生成场景下吞吐量提升明显。
关闭思考模式(纯聊天场景)
如果你的场景是常规对话或文本生成,不需要模型花额外 token 做反思:
bash
vllm serve Qwen/Qwen3.6-27B \ --tensor-parallel-size 2 \ --reasoning-parser qwen3 \ --default-chat-template-kwargs '{"enable_thinking": false}'
⚠️ **vLLM 大提示词预填充卡顿** DeltaNet 架构下,超长提示词的 prefill 阶段可能出现短暂卡住甚至报错。如果你的输入上下文超过 100K,考虑降低 `--max-model-len` 到 128K,或者改用 llama.cpp 方案(没有 prefill 瓶颈)。
方式二:SGLang(社区活跃,但注意兼容性)
SGLang 在 0.5.10 以上版本开始支持 Qwen3.6-27B。基础启动命令跟 vLLM 类似:
bash
# 安装 SGLanguv pip install sglang[all]# 启动服务(多卡场景推荐)python -m sglang.launch_server \ --model-path Qwen/Qwen3.6-27B \ --port 8000 \ --tp-size 8 \ --mem-fraction-static 0.8 \ --context-length 262144 \ --reasoning-parser qwen3 \ --tool-call-parser qwen3_coder
几点实测经验:SGLang 的 MTP/EAGLE 推测解码在代码生成场景下吞吐表现不错,但截至目前社区反馈 SGLang 对 Qwen3.6-27B 的某些配置有阻塞问题,稳定性不如 vLLM。优先选 vLLM,SGLang 可以作为备选方案探索。
方式三:llama.cpp + GGUF(单卡 / CPU / Mac 用户首选)
如果你只有 1 张显卡或者想在 Mac 上跑,llama.cpp 是最稳定的选择:
bash
# 克隆并编译git clone https://github.com/ggerganov/llama.cppcd llama.cppmake -j# 启动服务(以 4-bit GGUF 为例)./llama-server \ -hf unsloth/Qwen3.6-27B-GGUF:UD-Q4_K_XL \ --jinja \ --ctx-size 32768 \ --n-gpu-layers 99
UD-Q4_K_XL 量化级别在质量损失和显存占用之间做了很好的平衡,约 18 GB(含 RAM + VRAM 混合)。如果显卡显存不足,调低 --n-gpu-layers 把部分层卸载到 CPU。
Mac 用户可以用 MLX-4bit 方案:
bash
curl -fsSL https://raw.githubusercontent.com/unslothai/unsloth/refs/heads/main/scripts/install_qwen3_6_mlx.sh | shsource ~/.unsloth/unsloth_qwen3_6_mlx/bin/activatepython -m mlx_vlm.chat --model unsloth/Qwen3.6-27B-UD-MLX-4bit
需要 32 GB 以上统一内存(Mac Studio 或 M 系列 MacBook Pro)。
方式四:Transformers 原生推理(调试 / 开发用)
HuggingFace Transformers 直接用,适合快速验证和调试:
bash
pip install "transformers[serving]"transformers serve Qwen/Qwen3.6-27B --port 8000 --continuous-batching
生产场景不推荐,vLLM 或 SGLang 的吞吐量至少高出 2–3 倍。
方式五:MNN 移动端推理
阿里官方提供了基于 MNN 框架的 4-bit 量化版:
bash
git clone https://huggingface.co/taobao-mnn/Qwen3.6-27B-MNN
适合部署到手机、平板等端侧设备,在 iPhone 15 Pro 上可以达到 8–12 token/s 的生成速度。
验证服务是否跑通
不管你用哪种方式部署完,用一条 curl 命令就能验证服务状态:
bash
# 查询可用的模型列表curl http://localhost:8000/v1/models
成功时返回 JSON 格式的模型列表,包含模型名称和配置。接着发一个真正的推理请求:
bash
# 发送聊天请求curl -X POST "http://localhost:8000/v1/chat/completions" \ -H "Content-Type: application/json" \ -d '{ "model": "Qwen/Qwen3.6-27B", "messages": [{"role": "user", "content": "用 Python 写一个快速排序,加上注释。"}], "max_tokens": 512, "temperature": 0.0 }'
如果返回了完整的代码输出,服务就部署成功了。
Python OpenAI 客户端调用方式一样:
python
from openai import OpenAIclient = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY")response = client.chat.completions.create( model="Qwen/Qwen3.6-27B", messages=[{"role": "user", "content": "用 Python 写一个快排。"}], max_tokens=1024, temperature=0.0)print(response.choices[0].message.content)
开启思考模式需要在 extra_body 中传参:
python
response = client.chat.completions.create( model="Qwen/Qwen3.6-27B", messages=[{"role": "user", "content": "找出 1 到 50 之间所有质数并解释算法逻辑。"}], max_tokens=2048, extra_body={"chat_template_kwargs": {"enable_thinking": True}})
思考模式下,模型会在输出中先给出中间推理步骤,再给出最终答案。
微调:从 LoRA 到 QLoRA,数据格式与参数详解
Qwen3.6-27B 的微调生态比较成熟,Unsloth、Axolotl、TRL 都支持。下面以 Unsloth + QLoRA 为例,因为门槛最低——单张 RTX 4090 就能跑。
数据格式:ChatML 标准
Qwen3.6 使用 ChatML 格式(<|im_start|> / <|im_end|> 分隔),每一条数据都是一个 JSON 对象:
json
{ "messages": [ {"role": "system", "content": "你是一个精通 Python 开发的编程助手。"}, {"role": "user", "content": "请帮我优化这个 SQL 查询,它跑得太慢了。"}, {"role": "assistant", "content": "你的查询慢是因为在 WHERE 条件中对 order_date 用了函数包装。把 WHERE DATE(order_date) = '2026-06-01' 改成 order_date >= '2026-06-01' AND order_date < '2026-06-02',就可以利用索引了。"} ]}
每条数据三组角色:system(系统指令,可省略)、user(用户输入)、assistant(期望输出)。训练时重要的是只让模型学习 assistant 部分的内容,user 和 system 要构成 loss mask 不参与训练。
多轮对话也是同样的结构,user / assistant 轮流出现:
json
{ "messages": [ {"role": "system", "content": "你是一个 SQL 优化助手。"}, {"role": "user", "content": "SELECT * FROM orders WHERE DATE(order_date) = '2026-06-01';"}, {"role": "assistant", "content": "建议改用范围查询..."}, {"role": "user", "content": "我改成范围查询了,但还是很慢。"}, {"role": "assistant", "content": "检查一下 order_date 上是否有索引..."} ]}
数据准备模板
ChatML 数据存成 JSONL 文件(每行一个 JSON 对象),然后用 tokenizer.apply_chat_template() 格式化。Unsloth 做了封装,传入原始的 messages 列表就行。
⚠️ **模板不一致是最常见的微调失败原因** 用 `tokenizer.apply_chat_template()` 而非手动拼接 `<|im_start|>` 标签。Qwen3.6 的 tokenizer 已经内置了正确的模板,手动拼接容易在特殊字符上踩坑。
硬件门槛与量化选择
Unsloth 提供了不同量化级别的显存需求:
4-bit QLoRA 是性价比最高的方案:一张 4090 就能跑,效果能达到全量微调的 95–99%。BF16 全量微调需要双卡 A100,不是非必要不建议尝试。
实操:4-bit QLoRA 微调完整代码
以下是一份经过社区验证的完整微调脚本。复制到 train_qwen.py,调整数据路径即可运行:
python
from unsloth import FastLanguageModelfrom datasets import load_datasetfrom trl import SFTTrainer, SFTConfigfrom unsloth.chat_templates import get_chat_template, train_on_responses_onlymax_seq_length = 4096# 1. 加载 4-bit 量化模型model, tokenizer = FastLanguageModel.from_pretrained( model_name="unsloth/Qwen3.6-27B-bnb-4bit", max_seq_length=max_seq_length, load_in_4bit=True,)# 2. 设置 Qwen3 的 ChatML 模板tokenizer = get_chat_template(tokenizer, chat_template="qwen3")# 3. 注入 LoRA 适配器model = FastLanguageModel.get_peft_model( model, r=16, # LoRA 秩——16 够用,32 更好 target_modules=[ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", ], lora_alpha=16, # alpha = r 是 2026 年的主流选择 lora_dropout=0, bias="none", use_gradient_checkpointing="unsloth", use_dora=True, # DoRA:同秩下更接近全量微调质量 random_state=3407,)print(f"可训练参数量:{sum(p.numel() for p in model.parameters() if p.requires_grad):,}")# 4. 加载数据(JSONL 格式,每行一个对象含 "messages" 字段)dataset = load_dataset("json", data_files="my_training_data.jsonl", split="train")# 5. 使用 tokenizer 内置模板格式化数据def format_chat(example): text = tokenizer.apply_chat_template( example["messages"], tokenize=False, add_generation_prompt=False ) return {"text": text}dataset = dataset.map(format_chat, batched=False)# 6. 配置训练参数trainer = SFTTrainer( model=model, tokenizer=tokenizer, train_dataset=dataset, dataset_text_field="text", max_seq_length=max_seq_length, args=SFTConfig( per_device_train_batch_size=1, # 每卡 batch size gradient_accumulation_steps=16, # 有效 batch size = 1 × 16 = 16 warmup_steps=10, max_steps=300, # 或设 num_train_epochs=3 learning_rate=1e-4, logging_steps=10, optim="adamw_8bit", weight_decay=0.01, lr_scheduler_type="linear", bf16=True, seed=3407, output_dir="./qwen3.6-sft-output", ),)# 7. 关键步骤:只训练 assistant 回复部分trainer = train_on_responses_only( trainer, instruction_part="<|im_start|>user\n", response_part="<|im_start|>assistant\n",)# 8. 开始训练trainer.train()
超参数说明:
LoRA rank (r) = 16:对单任务微调够了。如果数据量大(超过 5000 条)或者任务复杂度高,可以加到 32,但显存占用也会上升。
LoRA alpha = r:2026 年的通用实践不再是 alpha = 2×r,1:1 比例在多个框架中验证为最优。
use_dora = True:DoRA 对权重做了幅值分解,同秩下 Loss 更低、收敛更快。Unsloth 默认支持,建议开启。
learning_rate = 1e-4:QLoRA 的常见起始值。如果发现 loss 不收敛可以先提到 2e-4,如果灾难性遗忘则降到 5e-5。
gradient_accumulation_steps = 16:单卡 batch 为 1,通过梯度累积模拟更大的有效 batch。16 步累积后有效 batch 为 16。
保存与导出微调结果
训练完成后,有三种保存方式:
python
# 选项一:仅保存 LoRA 适配器(小文件,加载时需要 base model)model.save_pretrained("qwen3.6-lora-adapter")tokenizer.save_pretrained("qwen3.6-lora-adapter")# 选项二:合并为 16-bit 完整模型(推荐给 vLLM 部署用)model.save_pretrained_merged("qwen3.6-merged-fp16", tokenizer, save_method="merged_16bit")# 选项三:导出为 GGUF(给 Ollama / LM Studio 用)model.save_pretrained_gguf("qwen3.6-finetuned-gguf", tokenizer, quantization_method="q4_k_m")
建议开发调试阶段只保存 LoRA 适配器(几十 MB),确认效果后再合并导出。
加载 LoRA 做推理
python
from unsloth import FastLanguageModel# 加载 base model(必须跟训练时一样的量化配置)model, tokenizer = FastLanguageModel.from_pretrained( model_name="unsloth/Qwen3.6-27B-bnb-4bit", max_seq_length=4096, load_in_4bit=True,)# 加载 LoRA 权重from peft import PeftModelmodel = PeftModel.from_pretrained(model, "./qwen3.6-lora-adapter")# 推理测试FastLanguageModel.for_inference(model)messages = [{"role": "user", "content": "测试 prompt"}]inputs = tokenizer.apply_chat_template( messages, tokenize=True, add_generation_prompt=True, return_tensors="pt").to(model.device)outputs = model.generate(inputs, max_new_tokens=1024, temperature=0.7)print(tokenizer.decode(outputs[0], skip_special_tokens=True))
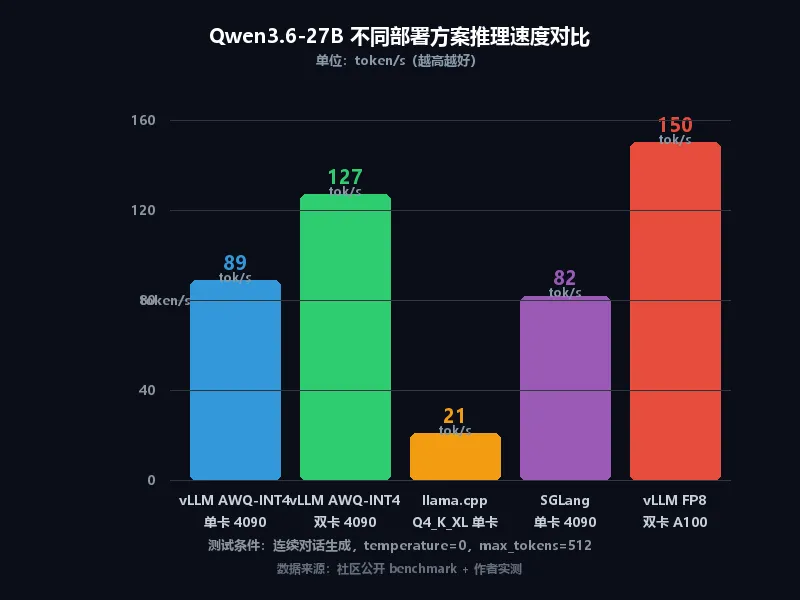
性能参考与成本评估
以下是社区实测的不同部署配置下的性能数据:
成本估算:自部署月成本 ≈ 显卡月折旧 + 电费。一张 RTX 4090 月折旧约 300–400 元,电费约 100–150 元(日均运行 8 小时)。对比 API 调用(OpenRouter 约 $0.30/百万输入 token),日调用量超过 500 万 token 时自部署更划算。
模型加载测试:完整流程
如果你不想启动服务,直接用 Transformers 加载模型做推理测试也很方便:
python
import torchfrom transformers import AutoProcessor, AutoModelForMultimodalLM# 加载 processor 和 modelprocessor = AutoProcessor.from_pretrained("Qwen/Qwen3.6-27B")model = AutoModelForMultimodalLM.from_pretrained( "Qwen/Qwen3.6-27B", device_map="auto", torch_dtype=torch.float16,)# 准备消息messages = [ {"role": "user", "content": [{"type": "text", "text": "解释一下量子计算的基本原理"}]}]# tokenizeinputs = processor.apply_chat_template( messages, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt",).to(model.device)# 生成outputs = model.generate(**inputs, max_new_tokens=100)# 解码response = processor.decode(outputs[0][inputs["input_ids"].shape[-1]:])print(response)
同样也支持多模态推理(输入图片):
python
messages = [ {"role": "user", "content": [ {"type": "image", "url": "https://example.com/photo.jpg"}, {"type": "text", "text": "这张图片里有什么?"} ]}]
如果显存有限,用 4-bit 加载:
python
from transformers import BitsAndBytesConfigbnb_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_compute_dtype=torch.float16, bnb_4bit_use_double_quant=True,)model = AutoModelForMultimodalLM.from_pretrained( "Qwen/Qwen3.6-27B", device_map="auto", quantization_config=bnb_config,)
总结
一张 RTX 4090 + AWQ-INT4 量化 = 跑得动的本地编程助手。想要更多能力,微调用 Unsloth 4-bit QLoRA 在单卡上就能完成。部署首选 vLLM,稳定性和性能都经过了社区验证。需要带回完整项目里用的,合并模型后导出为 16-bit 或 GGUF,跟推理框架对接就行。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
