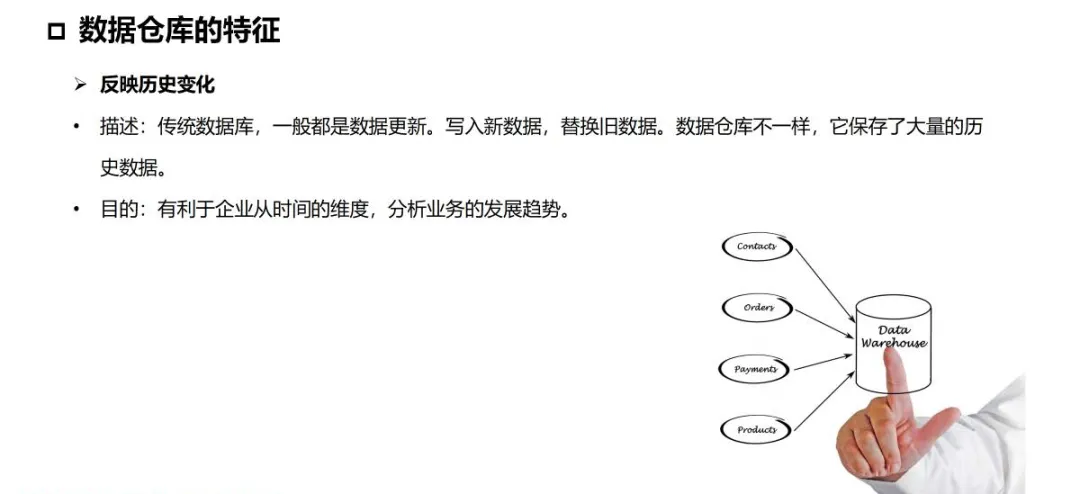
数据湖仓,也称为湖仓一体,是一种融合了数据仓库与数据湖优势的新型开放式数据架构。它旨在解决传统数据仓库与数据湖各自存在的局限性,为企业提供兼具灵活性、高性能与强治理能力的统一数据平台。
诞生背景与发展:
数据湖仓概念于2020年由数据智能公司Databricks正式提出,但其理念可追溯至更早的探索。此前,企业曾尝试通过两种路径结合数据湖与数据仓库:一是让数据仓库支持访问数据湖(如AWS Redshift Spectrum),二是增强数据湖的数据仓库能力(如Apache Iceberg、Delta Lake、Apache Hudi等项目)。然而,这些尝试因两者本质差异而存在整合难度。Databricks提出的数据湖仓架构,通过统一的元数据管理、ACID事务支持及开放格式,实现了湖与仓的深度集成,被认为是下一代数据架构的重要方向。
核心特点:
数据存储:继承数据湖的低成本、高扩展性优势,通常基于HDFS或云对象存储(如AWS S3),支持结构化、半结构化及非结构化数据的原始存储。
数据一致性:提供ACID(原子性、一致性、隔离性、持久性)事务保证,确保数据写入的一致性与可靠性,克服了传统数据湖在此方面的不足。
数据治理:通过统一的元数据管理、全局数据目录与全链路血缘追踪,实现高效的数据发现、权限管控与合规性管理,避免数据湖演变为“数据沼泽”。
处理模式:采用混合处理模式,既支持数据仓库的“Schema-on-Write”(写时模式),也保留数据湖的“Schema-on-Read”(读时模式)灵活性,满足多样化的分析需求。
性能与成本:在保持较低存储成本的同时,通过优化查询引擎(如Presto、Spark)和索引技术,提供接近数据仓库的高性能分析能力。
参考架构与实践:
当前主流架构分为“湖上建仓”与“仓外挂湖”两种路径:
国内外厂商已推出多种解决方案,例如AWS的Redshift Spectrum、Azure Databricks、Databricks Lakehouse,以及国内的阿里云MaxCompute、腾讯云TCHouse+DLC、华为云Fusion Insight等。
应用场景:
数据湖仓适用于需要同时处理批量分析、实时流处理、机器学习与商业智能(BI)的混合负载场景,帮助企业实现从原始数据探索到标准化报表的全链路数据分析,支撑数据驱动决策。
总结:
数据湖仓通过整合数据湖的灵活存储与数据仓库的高效治理,解决了数据孤岛、成本高昂与治理困难等传统问题,正成为企业构建现代化数据平台的关键架构。随着AI与数据系统的深度结合,数据湖仓将进一步推动数据智能应用的发展。
报告下载方式详见文末!










 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
