飞书文档附件文件下载RPA方案2.0来了!不仅是PDF,Word、PPT、Excel、视频都能批量导出了,还都是源文件
- 2026-07-13 14:29:21
"888"即可获得《RPA元素定位实战指南:XPath从入门到精通》电子版,直接送,无任何转发套路
*本文提及的"自动化获取「自动化下载飞书文档中PDF/PPT/视频/普通电子表格/Word」RPA应用",文末按提示联系我免费获取~
*更多RPA自动化应用解决方案见往期分享,有RPA自动化工具定制需求的老板后台滴滴~
在之前我写了一篇 下载「下载受限的飞书PDF文档」,通解3种不同资源类型的飞书域名,可以处理3种资源类型的飞书PDF文件下载:
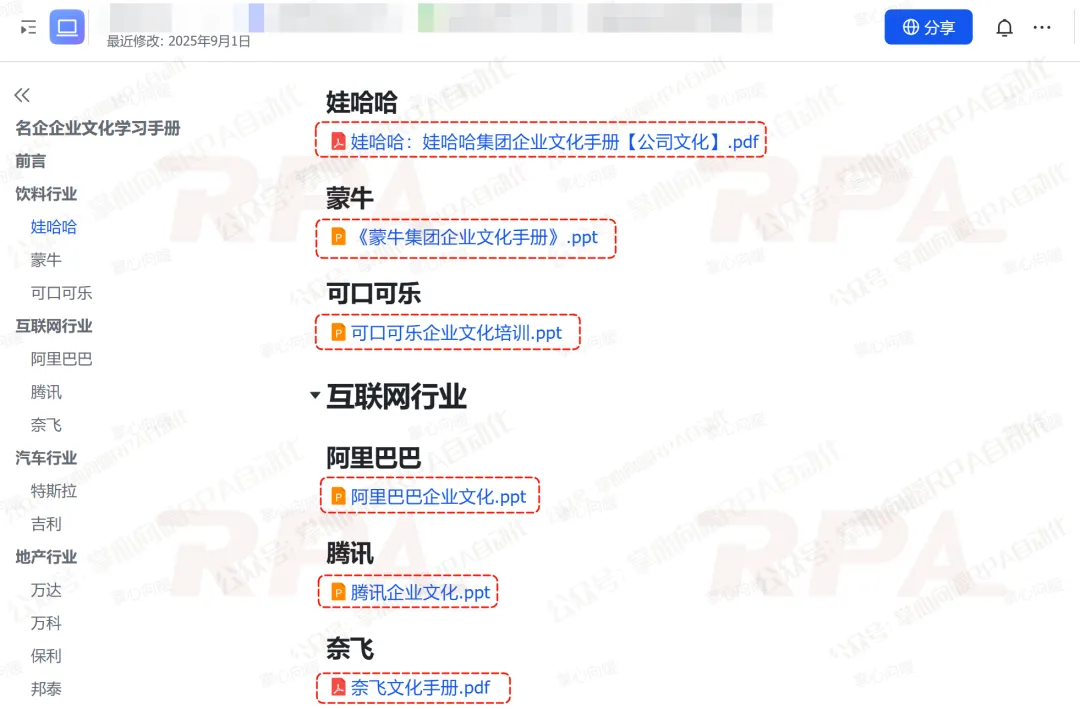
飞书文件(file附件):https://*.feishu.cn/file/*
飞书文档(Word类型):https://*.feishu.cn/docx/*
飞书知识库(Wiki页面):https://*.feishu.cn/wiki/*
但这种方案是通过【自动化翻页截图+图片合并成PDF】实现的,它能用,但问题也很明显:
处理速度极慢(页数越多越崩溃) 输出结果是"图片型PDF"(不便检索、复制、二次编辑) 对很多需要"可编辑源文件"的场景并不友好
痛点就是优化的动力!最近我又重新研究出一套更快、更"硬核"的方案:
还是通过影刀RPA来承载/实现的,只不过这次我们无需再逐个翻页截图拼接,而是直接"监听+请求"进行源文件的下载,
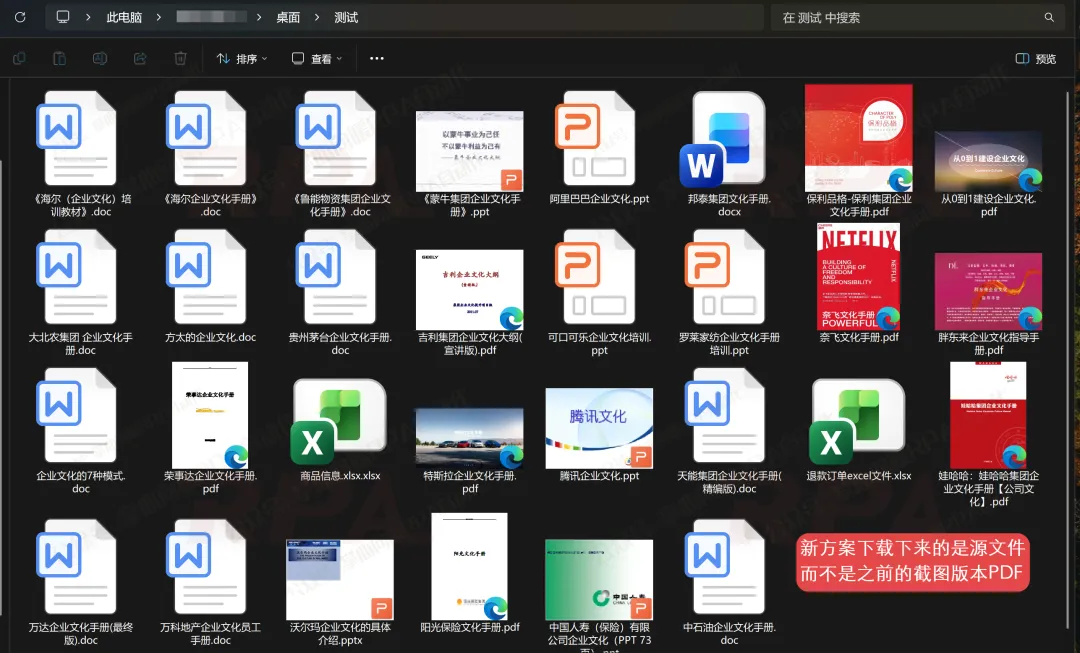
且支持下载的文件类型从仅支持PDF,升级到支持PDF、PPT、视频、普通电子表格、Word文档五大常规文件类型快速下载。
#关于"飞书文档类型"的信息补充:
▪ 内嵌文档(嵌入主文档)- 将外部文件(Word、PDF、Excel、PPT等)上传后嵌入到飞书文档中
▪ 独立文档(独立视图)- 上传的文件独立存在,有单独的访问链接
下面来看一下详细介绍和实现思路。
一、应用介绍
这是一款基于影刀RPA开发的"自动化下载飞书文档中PDF、PPT、视频、普通电子表格、Word文件的RPA机器人(网页自动化)"。
不管文件是独立存在还是内嵌在飞书文档,都能直接下载源文件。
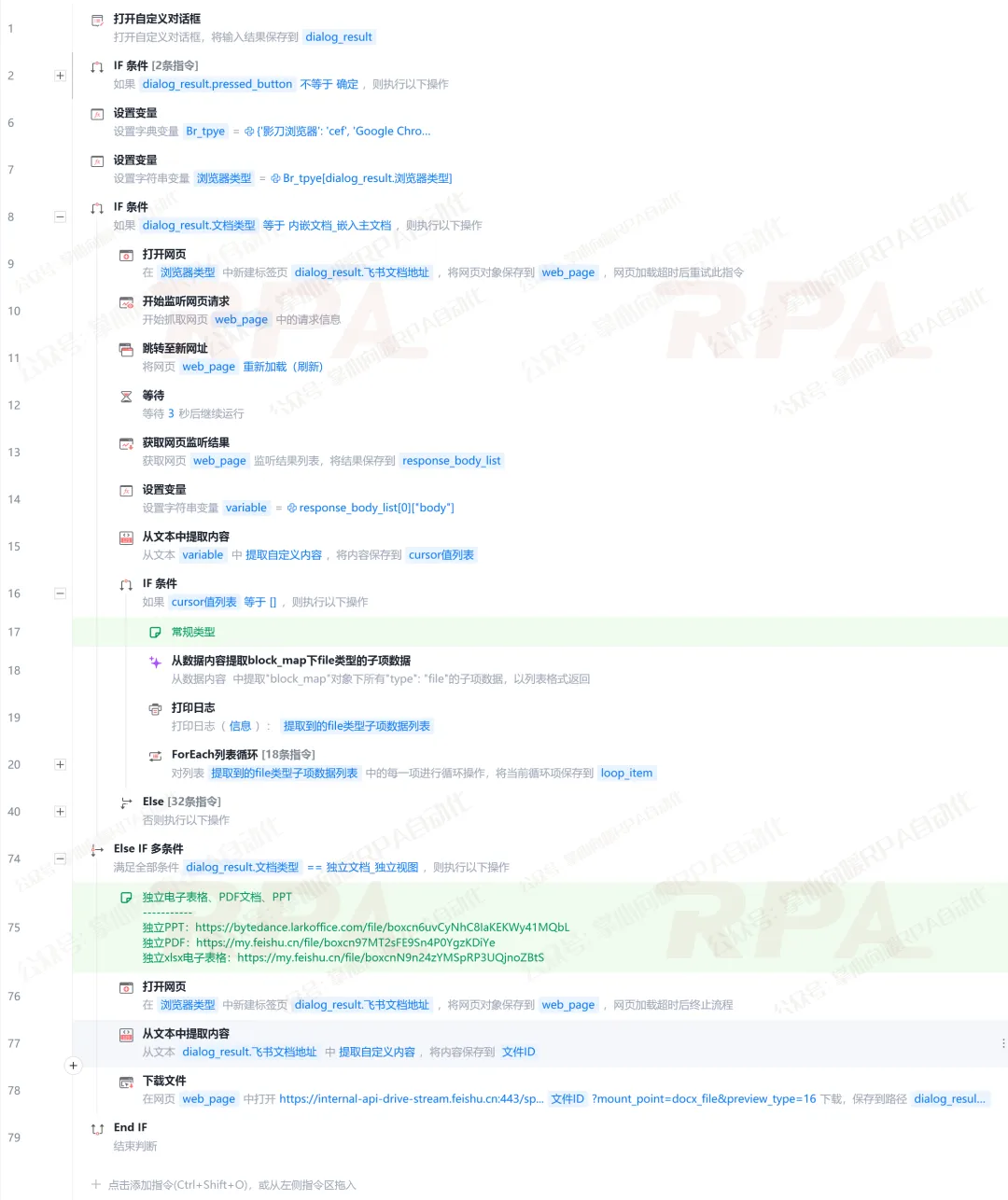
目前支持的具体功能点:
支持两类常见飞书附件/嵌入文件结构。「内嵌文档(嵌入主文档)」:外部文件上传后嵌入飞书文档中;「独立文档(独立视图)」:文件独立存在,有单独访问链接
支持源格式文件下载:原文件是什么格式,下载下来就是什么格式
支持自定义保存路径:可自定义下载保存位置,方便分类管理
支持自定义浏览器运行:可选择谷歌、360、Edge等主流浏览器运行
内嵌文档支持"选择下载类型":可选择只下载:视频/PDF/PPT/表格/Word,默认全部下载
二、核心实现思路
V1.0版本是模拟人的眼睛(截图),V2.0版本则是模拟人的耳朵(监听)。该应用采用了"网页监听 + HTTPS请求"的策略,核心逻辑在于监听飞书文档加载时的接口响应。
这里有一个难点,我们实际要监听的资源路径(Request URL)有以下两种类型,需要分别处理。
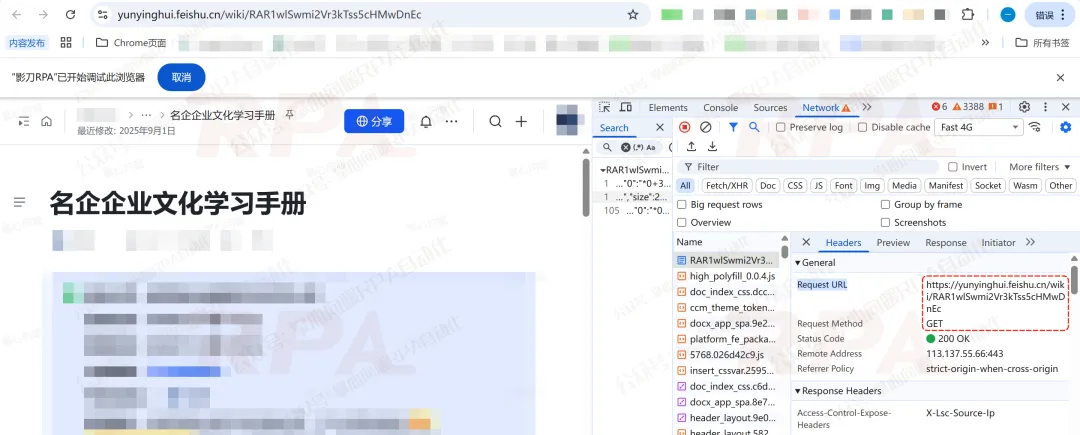
第1种:传入的飞书文档地址
也就是在应用启动参数里输入的飞书链接。RPA机器人先打开它,并从页面加载过程里拿到关键接口的返回值。
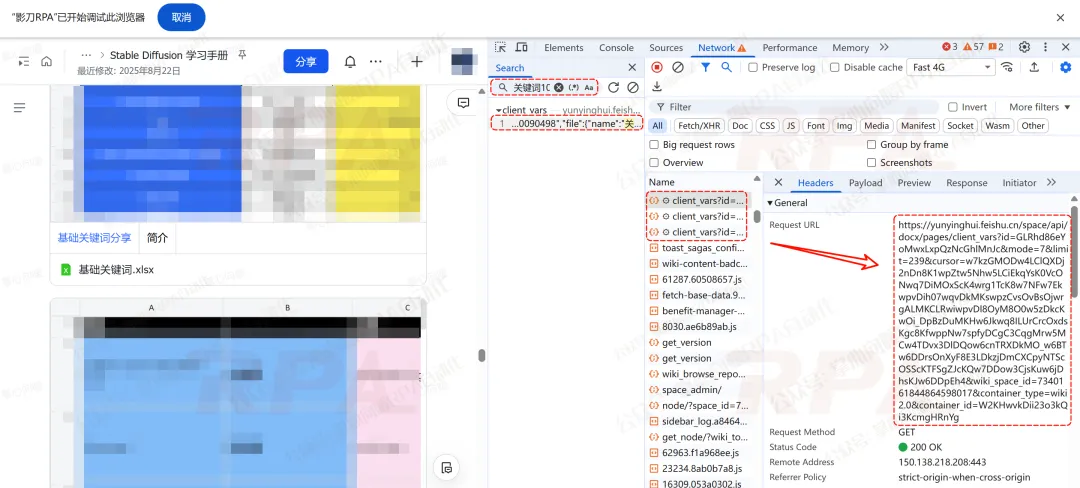
第2种:另一类特殊 Request URL
这类URL格式为:https://...feishu.cn/space/api/docx/pages/client_vars?id=...&mode=7&limit=239&cursor=...&wiki_space_id=...
找到它后,直接发起请求,从响应数据中解析出附件/嵌入文件的下载信息。
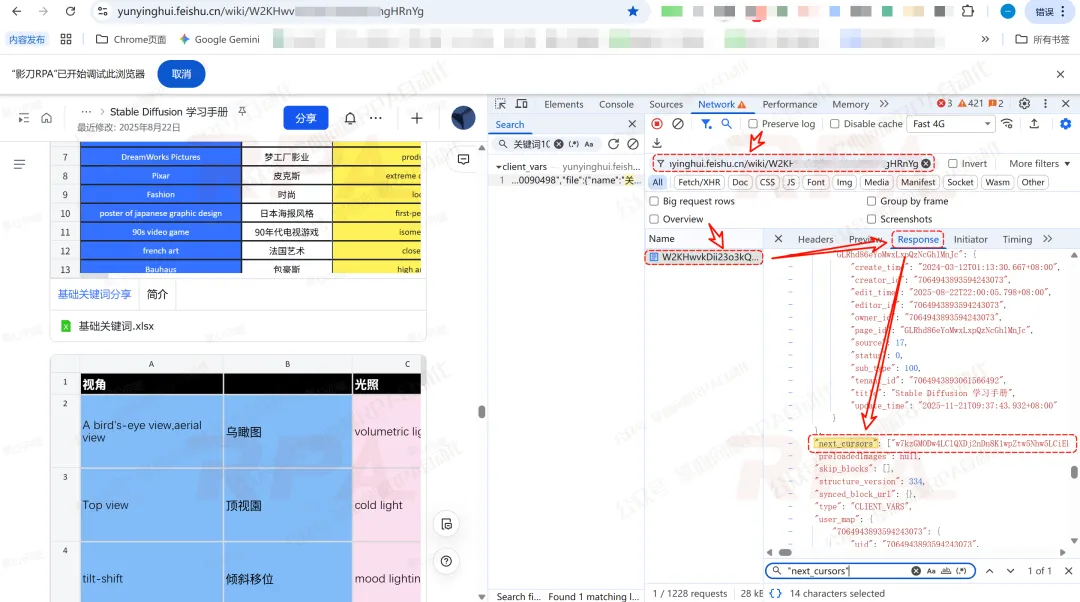
为了让你实现无感下载,我从“传入的飞书文档地址”返回的响应中获取了这个Request URL中的变量值,从而还原出这个资源路径:
【文档域名】/space/api/docx/pages
/client_vars?id=【obj_token】&mode=7&
limit=239&cursor=cursor
值&wiki_space_id=【space_id】&container_type=wiki2.0&container_id=【wiki后面的ID】,
这样就能做到:用户只需要复制飞书链接 → 机器人自动推导接口 → 自动解析 → 自动下载源文件。
三、如何获取 & 应用?
1. 启动参数说明
启动应用后,用户需要依次选择以下参数:
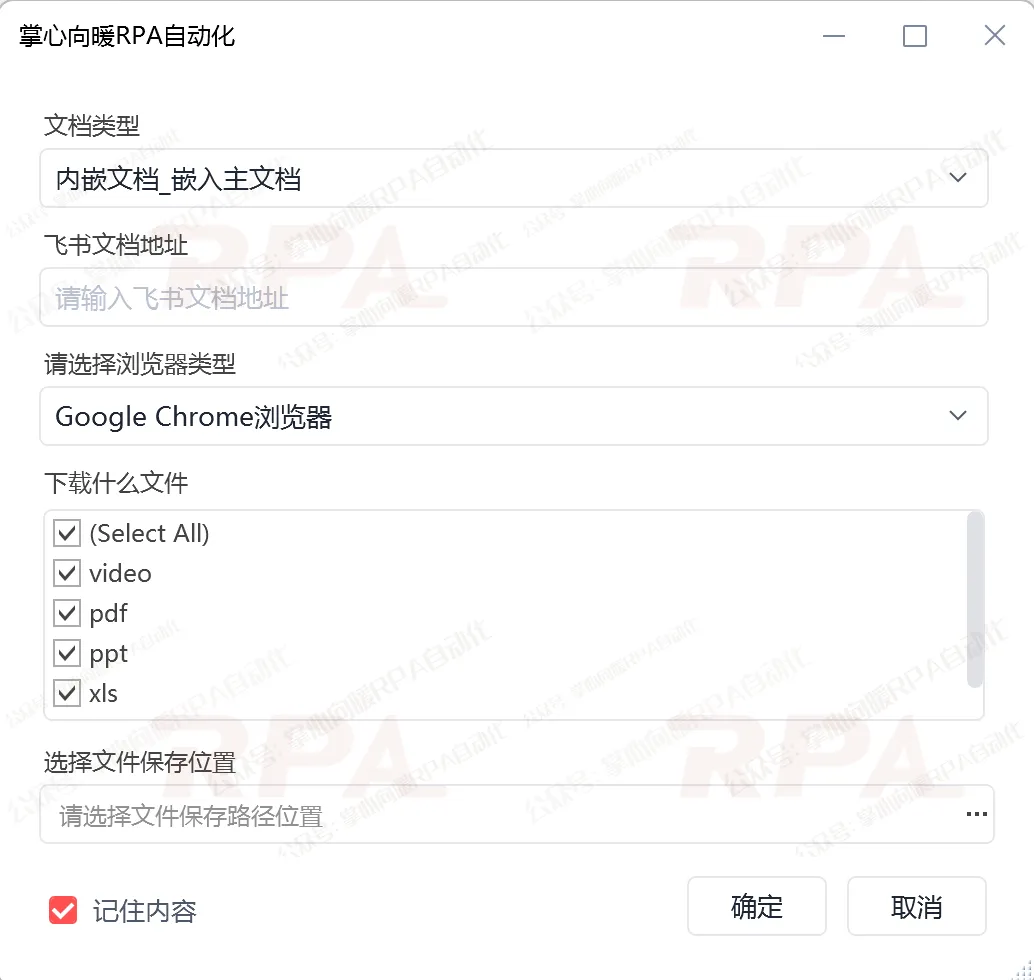
文档类型:根据文件类型自行选择"内嵌文档_嵌入主文档"或者"独立文档_独立视图"
飞书文档地址:请输入飞书文档地址 请选择浏览器类型:自定义选择Google Chrome浏览器等主流浏览器运行 下载什么文件:视频、PDF、PPT、普通电子表格、Word 选择文件保存位置:请选择文件保存路径
2. 使用环境 / 工具配置
为了保证机器人运行稳定,需满足下面这几个基础环境:
需要影刀RPA账号:https://www.yingdao.com 使用Chrome 浏览器或其他支持的浏览器。 安装影刀自动化插件,软件右上角头像点击 [工具-自动化插件]。
应用暂时只支持 Windows 端,其他设备自行测试 浏览器提前登录飞书账号 浏览器"下载设置"中关闭"下载前询问每个文件的保存位置"
3. 使用注意事项
运行过程中不要切换或关闭浏览器页面。
下载速度/稳定性与网络加载速度、文件本身大小有关,不要开魔法,静待处理完成。
该应用仅供下载用户拥有授权的飞书文档文件,禁止用于下载受版权保护且未经授权的内容。用户需自行承担使用本工具的全部法律责任,开发者不对用户的任何行为负责。
4. 获取应用
帮我这篇分享点个“関注&赞&推荐”,然后加我微信免费获取应用(*推荐)。
不方便点的,文末打赏9.9元,凭打赏截图添加我微信 PD-1104 领取。


你有没有算过,每天多少时间浪费在重复操作上?未来,自动化将是职场的基础能力。掌握RPA,你就能把重复的工作交给机器人,把创造力留给自己。


2. 如果你希望及时获取最新推送,请关注本公众号并标星⭐。
3. 扫描下方二维码,无套路领取《XPath元素定位指南简略版及辅助插件》。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 新闻出版行业标准合集分享(可免费下载)
- 【免费下载】消防控制室资料合集(完整可编辑)
- 免费下载2026 Perfectly Clear WorkBench v5.0.1.3051 for win中文汉化版软件安装包ai智能图像瑕疵处理摄影师照片ai美化工具
- 金山打字通2016安装教程及下载!支持 Windows 10、11
- WPS2025(官方版)附下载链接及安装教程
- 西瓜视频咋下载保存?从手机录屏到命令行,5种方法任你选,用错工具费时间!
- ACDSee2026软件包下载及安装教程
- 2026春新教材电子课本+配套资料打包下载方法
- 轻花优品借款App下载安装全攻略,从渠道选择到使用注意事项,一应俱全
- 500份!ESG实用资料大全,0元免费领!(附下载)
